Feeds 3
Artículos recientes
Nube de tags
seguridad
mfa
dns
zerotrust
monitorizacion
kernel
bpf
sysdig
port knocking
iptables
linux
pxe
documentación
rsyslog
zeromq
correo
dovecot
cassandra
solandra
solr
systemtap
nodejs
redis
hadoop
mapreduce
firewall
ossec
psad
tcpdump
tcpflow
Categorías
Archivo
Proyectos
Documentos
Blogs
Monitorización de aplicaciones con sysdig Wed, 23 Nov 2016
Historicamente, uno de los argumentos más importantes de la comunidad Solaris en relación a la, no sé si decirlo así, madurez de Linux para entornos profesionales, ha sido la falta de instrumentalización para la monitorización del sistema.
En realidad, no faltaba razón en este argumento, ya que los primeros esfuerzos, por ejemplo de la mano de Systemtap, no conseguían llegar a lo que ofrecía el fantástico Dtrace en este tipo de entornos. A pesar de haber pasado ya varios años, no creo que ninguna de estas aplicaciones haya llegado a un público masivo (en el ámbito empresarial, claro).
Sin embargo, gracias al trabajo de mucha gente, estos últimos meses están siendo espectaculares para dotar a Linux, por fin, de herramientas capaces de igualar a Solaris. De hecho, alguna de las cabezas pensantes detrás de Dtrace, como Brendan Gregg, ahora trabajando en entornos Linux, ha venido a decir que ha sido como si, después de haber estado esperando al autobús, de repente hubiesen llegado dos. Os recomiendo esta lectura, con algo de contexto sobre la evolución de estas nuevas herramientas.
Hoy en día, como decía, tenemos varias alternativas. Personalmente, estoy interesado en dos: a) eBPF, o ya últimamente BPF, a secas, y b) Sysdig.
Con BPF se está dotando al Kernel Linux de toda la instrumentalización necesaria para inspeccionar al detalle el funcionamiento del sistema. A partir de ahí, un toolkit como BCC hace uso de todas estas nuevas estructuras para facilitar la manipulación de estos datos a través de un interfaz Python o Lua. Echad un vistado a la web. Los ejemplos son particularmente interesantes.
El soporte para BPF está integrado en los Kernels estándar recientes. Es algo en plena evolución, así que, si queréis probarlo, os recomiendo que no uséis nada inferior a 4.4, aunque ya haya cosas desde antes. En realidad, la cosa va tan rápido que, ya puestos, lo mejor es que probéis con 4.9 para ver lo último de lo último que se ha incluido.
Parece claro que se tienen muchas espectativas puestas en BPF. Hay varios proyectos importantes que ya se están planteando su uso. SystemTap, por ejemplo, está empezando a implementar un backend bajo BPF. Por otro lado, y bajo el mismo paraguas de BPF, se están desarrollando nuevas tecnologías, como XDP, que prometen una serie de ventajas que ya se están empezando a contemplar en el mundo de las redes software o los contenedores. Si queréis leer algo sobre esto, aquí tenéis un enlace.
La segunda alternativa de la que os hablaba, Sysdig, aunque para el usuario final que solo quiere monitorizar sus sistemas tenga, por así decirlo y cogido con alguna pinza, el mismo objetivo que BPF, lo hace de una manera diferente. Instrumentaliza el Kernel y ofrece un backend de calidad, pero delega gran parte del trabajo a filtros y a pequeños scripts, que llaman chisels (en Lua), que se encargan del trabajo desde el punto de vista del usuario.
En este momento, si dejáis de leer este post e investigáis por vuestra cuenta durante una hora, seguramente lleguéis a la conclusión de que BPF es realmente potente, pero que cuesta empezar (hay mucho hecho ya bajo el paraguas de iovisor, y cada poco sale un nuevo script). Por otro lado, es probable que en esa misma hora lleguéis a entender de qué va Sysdig, y que aunque no sea tan "amplio" como BPF, en realidad es más que suficiente para muchos de los problemas que habitualmente tiene el usuario de a pie. Ojo, que no estoy diciendo que Sysdig sea mejor que BPF, ni remotamente. Sacad vuestras propias conclusiones, pero leed sobre ambos y probadlos antes.
Tanto BPF como Sysdig dan para muchos posts. Os recomiendo leer el blog de Brendan Gregg, la documentación y los ejemplos de github de iovisor, y el blog y la web de Sysdig para ir calentando.
Mi idea original para el artículo era usar Sysdig en algún script real, pero eso lo haría mucho más denso, y he preferido limitarlo a algunas notas de lo que se puede hacer, aunque lo disfrazaré de ejemplo real.
Imaginad que tenéis un script que procesa un fichero de logs. En función de la expresión regular va a una u otra rama de código y, al final, inserta los resultados en mysql. En un entorno real, seguramente paralelizaríamos el script para aprovechar todos los cores, quizá usando zeromq para el paso de mensajes, y quizá usando el patrón que algunos llaman pipeline. Los entornos paralelos suelen complicar la monitorización.
Vamos a suponer la locura (irónico) de que no tenemos tiempo para la optimización o el análisis de ningún script, mucho menos si es cosa de horas, y todavía menos si el mencionado script no funciona rematadamente mal.
Y aquí es cuando alguien se levanta y dice: "Tanto rollo para algo que se puede solucionar con las trazas de toda la vida, (inicio = time.time(); fin = time.time(); dif = fin - inicio) ". No seré yo el que diga que este tipo de trazas no funcionen, aunque estaremos de acuerdo en que son "limitadas". Sirven para decir que algo va lento, pero no el motivo; aparte del tiempo que lleva procesar, digamos, 80 millones de lineas de log multiplicadas por tantos "ifs" como tenga el código, que además se ejecutan en procesos independientes. Es viable, por supuesto, pero mejorable.
Afortunadamete, ya habéis dedicado una hora a mirar tanto Sysdig como BPF/BCC y, claro, habréis llegado a la conclusión de que cualquiera de las dos os pueden servir. Veamos qué podemos hacer con Sysdig.
Repasemos: Una vez instalado Sysdig (os lo dejo a vosotros), se carga un módulo de Kernel que, simplificando un poco, va a ir recogiendo, eficientemente, los datos que se vayan generando (llamadas al sistema, IO, ...), de tal manera que luego se puedan aplicar filtros y chisels que nos den la información que necesitemos.
Además, tenemos suerte, porque una de las últimas funcionalidades que se han añadido a Sysdig consiste en algo tan sencillo como marcar el inicio y el fin de un bloque de código, y usar después estas marcas para el análisis. Imaginad que tenéis la capacidad de saber fácilmente la distribución del tiempo que necesita un "if" que incluye algunas operaciones sobre una base de datos; y que además podéis saber sin nada de esfuerzo el contenido íntegro del "select" que se mandó a la base de datos, o si falló la conexión o la resolución del nombre de la máquina bbdd para ese pequeño porcentaje de bloques lentos.
Y todavía es mejor, porque para hacer esto de lo que os estoy hablando solo hay que escribir una cadena concreta en /dev/null. Es previsible que esto será muy fácil, sea cual sea el lenguaje que estéis usando. Mirad estos ejemplos, sacados directamente de la web de sysdig.
echo ">:p:mysql::" > /dev/null
... código a analizar ...
echo "<:p:mysql::" > /dev/null
Y así de fácil. Con > y < definimos el comienzo y el final del bloque, con :p: pedimos que se genere un identificador automáticamente a partir del pid del proceso (hay más opciones), y usamos mysql como tag para identificar el span (que es como se llama todo esto, tracer/span).
Pero podemos ir un poco más lejos, y usar cadenas como las siguientes:
echo ">:p:mysql.select::" > /dev/null
echo ">:p:mysql.update::" > /dev/null
echo ">:p:mysql.select:query=from tabla1:" > /dev/null
echo ">:p:mysql.update:query=tabla1:" > /dev/null
Como veis, podemos anidar tags, o incluso añadir argumentos que den más pistas sobre lo que hace cada bloque. Esto es muy útil para saber la iteración exacta dentro de un for en la que ha ocurrido un problema concreto, o el tipo de select que ha generado cierto error, por decir un par de casos.
Volviendo a lo nuestro, recordad, queremos tener controlado un script python que escribe en una base de datos, que usa zeromq, y que se basa en expresiones regulares para hacer una cosa u otra. Sin pensar mucho, tendríamos una estructura de código parecida a esta:
fsysdig = open("/dev/null/", "w")
# Abrimos fichero log, creamos procesos, ...
for linea in fsysdig:
fsysdig.write(">:p:zmq::\n")
fsysdig.flush()
# Preparamos los datos, y mandamos al socket push de ZMQ
# Este socket se bloquea al llegar al tope de memoria configurado
# ...
socketzmq.send_multipart(["LOG",linea])
# ...
# Mas actividad para este span
fsysdig.write("<:p:zmq::\n")
fsysdig.flush()
En otros procesos tendremos la parte de la gestión de las expresiones regulares
fsysdig = open("/dev/null/", "w")
#
# Leeriamos del socket push via un socket pull de ZMQ
# ...
#
while seguirprocesando:
# Hacemos match de una expresion regular
# Si se cumple, hacemos ciertas operaciones
# ...
if matchregexp1:
fsysdig.write(">:p:regexp:re=regexp1:\n")
fsysdig.flush()
# Trabajo con la regexp1
# ...
# Enviamos el dato al proceso mysql via ZMQ
# ...
fsysdig.write("<:p:regexp::\n")
fsysdig.flush()
if matchregexp2:
fsysdig.write(">:p:regexp:re=regexp2:\n")
fsysdig.flush()
# Trabajo con la regexp2
# ...
# Y enviamos el dato al proceso mysql via ZMQ
# ...
fsysdig.write("<:p:regexp::\n")
fsysdig.flush()
#
# Hariamos algo parecido con el resto ...
#
Ya os hacéis una idea. Como veis, estamos añadiendo argumentos al tag regexp para identificar los bloques.
Por último, otro proceso haría el trabajo contra mysql.
fsysdig = open("/dev/null/", "w")
while seguirprocesando:
#
# Leeriamos del socket push via ZMQ, agrupariamos, operaciones, ...
#
try:
fsysdig.write(">:p:mysql:st=update:\n")
fsysdig.flush()
# preparariamos la operacion mysql y el resto del trabajo para este span...
cur.execute('''insert into ...''')
# ...
except (MySQLdb.MySQLError, TypeError) as e:
print "Mysql: ERROR: Al ejecutar comando mysql " + str(e)
sys.stdout.flush()
finally:
# ...
fsysdig.write("<:p:mysql::\n")
fsysdig.flush()
Como veis, también hemos creados argumentos para identificar bloques.
Este es el tipo de código que vamos a ejecutar. Antes de eso, vamos a poner en marcha la captura de sysdig (se puede lanzar en cualquier momento).
sysdig -C 500 -s 512 -w volcado_span.scap
Básicamente estamos creando ficheros independientes de 500MB, y estamos capturando 512 bytes de bufer de IO.
Una vez tengamos Sysdig lanzado dejamos el script funcionando un rato. Tendremos varios ficheros volcado_span.scap[0-9]+. Empecemos el análisis!
Una de las utilidades principales de Sysdig es un interfaz ncurses que permite ejecutar chisels fácilmente. Se llama csysdig. En nuestro caso, vamos a leer uno de los volcados para simplificar el proceso, pero tened en cuenta que todo esto se puede hacer sobre una captura en tiempo real, sin el parámetro -r
csysdig -r volcado_span.scap8
En este listado, F2 -> Traces Summary, y nos dará el resumen de spans que se han generado.
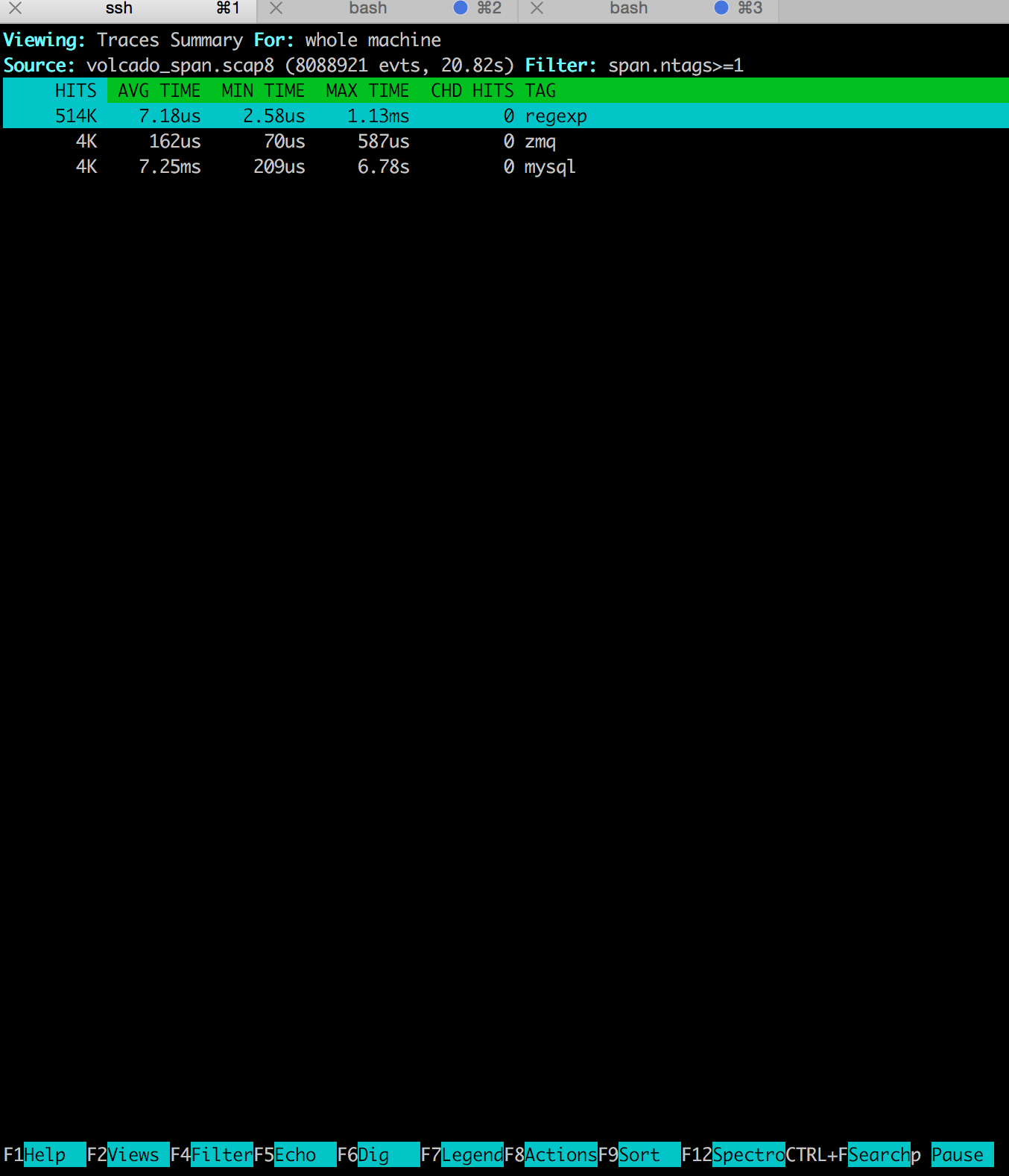
Hagamos algo más interesante. Uno de los chisels más visuales que ha escrito la gente de Sysdig se llama "spectrogram", y se utiliza para ver la distribución de las latencias de ciertos eventos. Csysdig integra una versión que muestra la distribución para los spans, como una unidad. Os dejo que la veáis vosotros (hay videos en los tutoriales de la web de Sysdig). Aquí vamos a ser un poco más brutos y vamos a mostrarla para todos los eventos que se generan dentro de los bloques con el tag "regexp":
sysdig -r volcado_span.scap8 -c spectrogram 'evtin.span.p.tag[0]=regexp'
De donde sacaríamos lo siguiente:
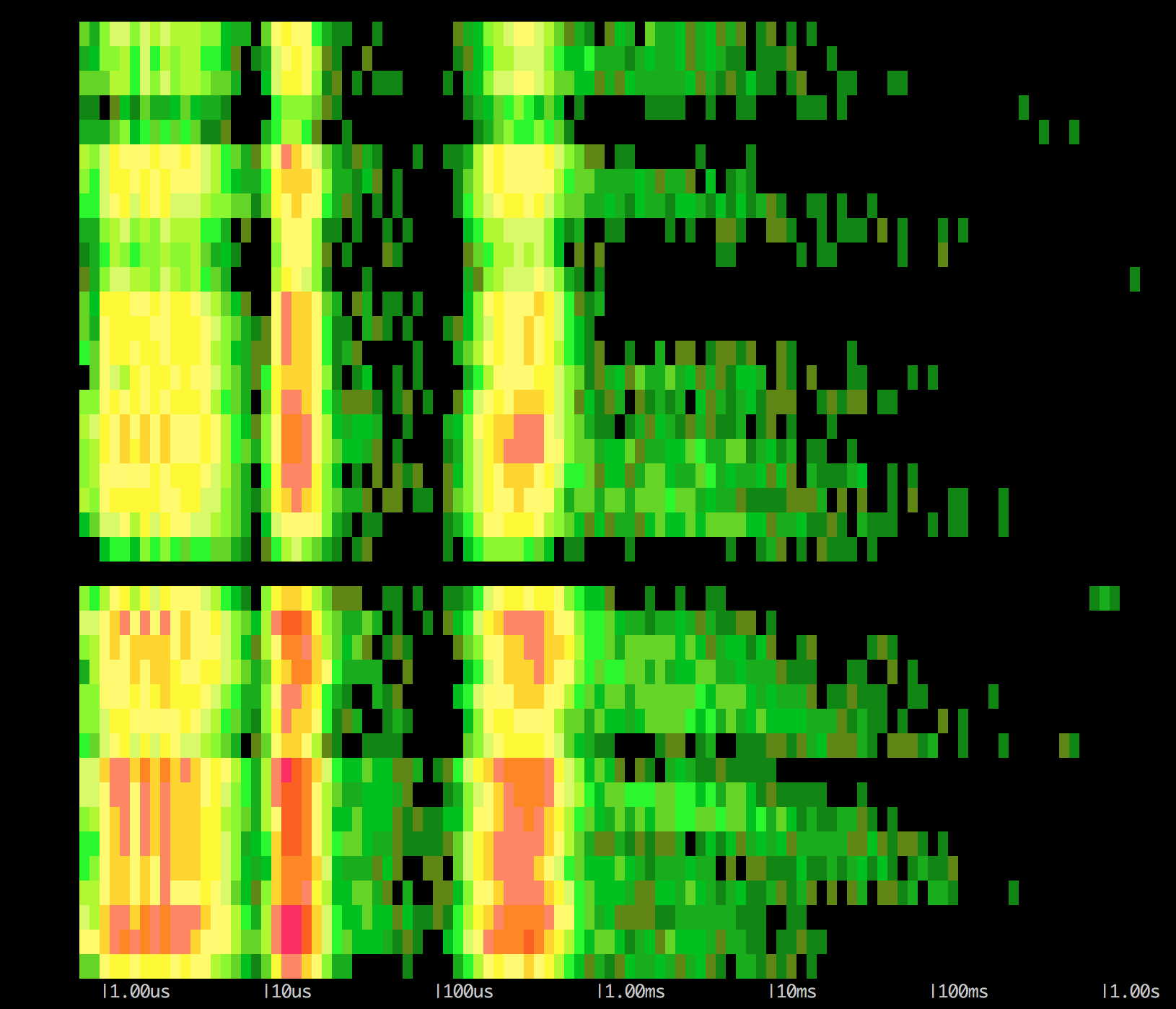
Aunque lo que os muestro no es demasiado práctico (seguramente sea más interesante empezar por spans en bloque), imaginad que tenéis accesos a red o llamadas más costosas, y que tenéis mucho rojo hacia la derecha (muchos eventos y muy lentos). Esos serían, quizá, los eventos más interesantes a analizar:
sysdig -r volcado_span.scap8 -c spectrogram 'evtin.span.p.tag[0]=regexp and evt.latency > 100000'
Como veis, estamos aplicando filtros para limitar lo que vemos:
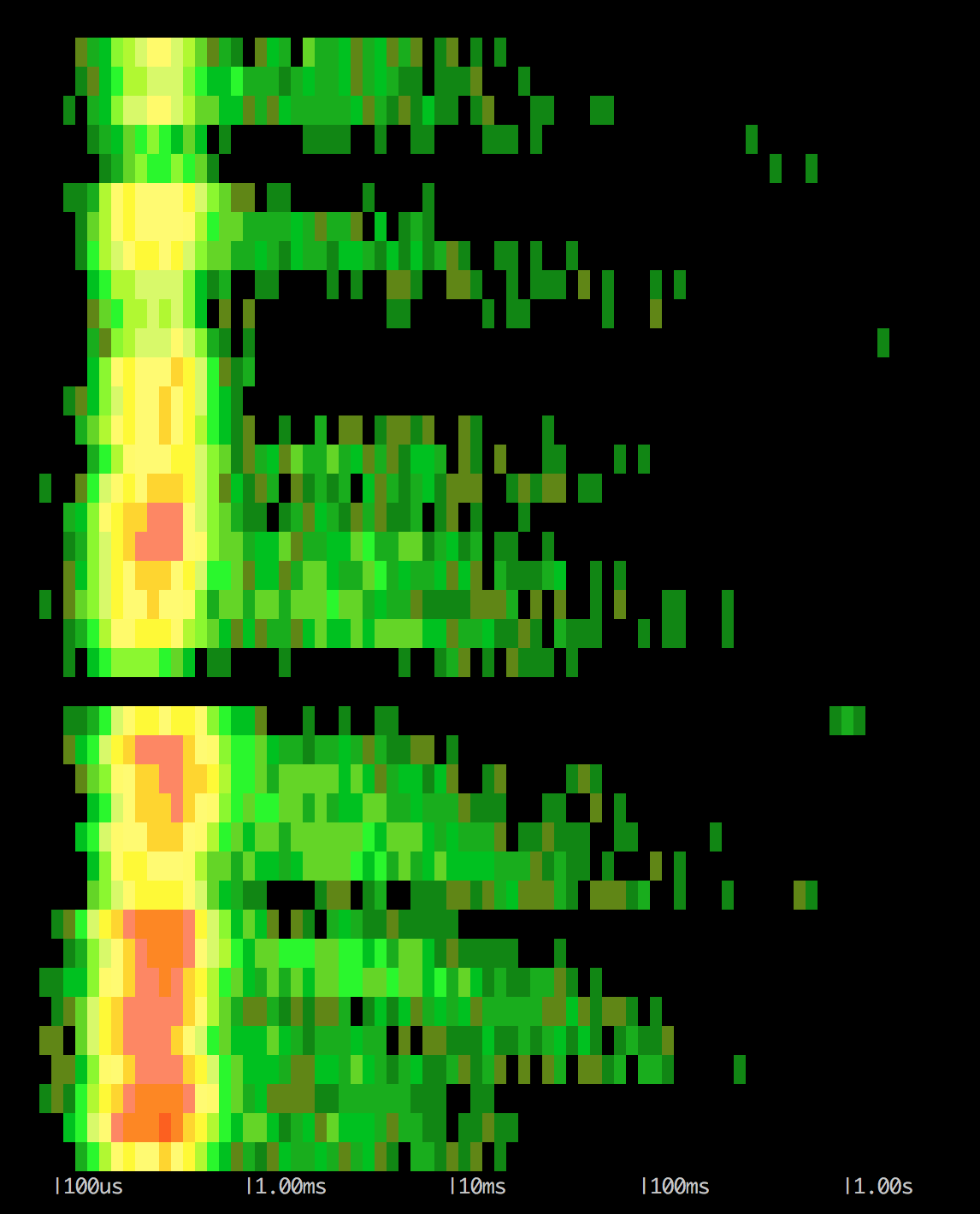
Este tipo de imágenes me parecen interesantes para ver si hay algún tipo de anomalía o algo que no nos parezca razonable; aunque en un caso real antes o después dejaríamos de usar los chisel visuales y pasaríamos a ver los eventos concretos que están dando guerra. De hecho, la vista spectrogram de csysdig permite elegir con el ratón partes de la imágen para pasar a modo texto.
Y esto es, para mí, de lo mejor de Sysdig: Podemos limitarnos a grandes sumarios como los que hemos visto hasta ahora, o a ver lo que está ocurriendo a nivel de llamada a sistema. Además, aunque en este artículo nos hemos centrado en un análisis "a posteriori", en la práctica podemos lanzar csysdig en tiempo real y tener integradas en un mismo interfaz todas las funcionalidades, mejoradas, que dan comandos como htop o netstat, por citar un par.
Depende del caso de uso de cada uno. Yo, por ejemplo, en el día a día uso Sysdig sobre todo para ver el tráfico entre sockets. Por ejemplo, imaginad que tenéis algún tipo de middleware que hace llamadas HTTP a un servicio externo en función de las peticiones HTTP que recibe. Suponed que no logueáis esas peticiones, y que a veces fallan. En estos casos Sysdig es realmente útil.
El chisel echo_fds, por ejemplo, es muy interesante porque muestra todo el IO de los eventos que cumplan el filtro que apliquemos. Además, lo colorea en función de si es de entrada o de salida. Por supuesto, se puede usar para HTTP, como he comentado, pero también con cualquier otro proceso que genere IO, como por ejemplo, mysqld:
sysdig -r volcado_span.scap11 -c echo_fds 'proc.name=mysqld'
Nos hemos olvidado de los spans, como veis, y vamos directamente a los procesos mysqld. Sin acotar más, tendremos un churro similar al siguiente
.....
------ Read 4B from 127.0.0.1:52398->127.0.0.1:mysql (mysqld)
....
------ Read 87B from 127.0.0.1:52398->127.0.0.1:mysql (mysqld)
.insert into tabla(timestamp, dato1, dato2) values (1477905741, 'ejemplo1', 'ejemplo2')
------ Write 11B to 127.0.0.1:52398->127.0.0.1:mysql (mysqld)
......
Como veis, estamos logueando todo el tráfico SQL, como el insert que he dejado aquí. Creedme, este tipo de chisels, con filtros como evt.buffer contains son muy útiles para ver tráfico HTTP, cabeceras, respuestas o códigos de error, particularmente en entornos con muchos microservicios y similares.
En fin, no sé si os habéis hecho una idea de lo que se puede hacer con Sysdig. En realidad, no os he dicho nada del otro mundo; teneis mucha mas informacion en la web y el blog de Sysdig, por citar dos fuentes. En cualquier caso, la unica forma de coger soltura con esto es con el uso, asi que lo mejor que podéis hacer es probarlo.
En comparación a lo que hemos hecho, y aprovechando que estamos hablando de mysql, en este enlace tenéis el ejemplo de cómo se mostrarian las consultas lentas con BPF/BCC. Si seguís el texto del enlace, veréis que podéis usar lo que ya esta hecho (usando el script mysqld_query.py de los ejemplos de BCC, o que también podéis pedir pizza y café y llegar a muy bajo nivel gracias al uso que puede hacer BPF/BCC de la instrumentalización que ofrece mysql, antes principalmente para Dtrace, y ahora también para Linux. En todo caso, mejor si leéis el post (y el resto de la web) de Brendan Gregg para ir sacando más conclusiones.